

こんにちは。今回は概念モデリングの興味深い記事「Conceptual modelling for the rest of us with ConML」について、著者のCésar González-Pérezさんに許可をいただき(Gracias!)翻訳しました。エンジニアリングではない分野でもモデリングが活躍していることが紹介できればと思います。
ソフトウェア技術者以外の人々のためのConMLによる概念モデリング
概念モデリングはふつうソフトウェア工学の文脈で語られる。しかし、実際にはソフトウェアに限らず、様々な種類のアーティファクト(人工物)に関する形式化や調査、文書化、理解、コミュニケーションにおいて概念モデリングは有用な技術である。事実、および20年にわたる文化遺産の領域における我々の経験から確実にいえることは、人文科学や社会科学の分野でも多くの概念モデリングが行われていることである。それらの分野の人々は必ずしもソフトウェア技術者と同じ用語を使っているとは限らず、またその形式化の程度も、ソフトウェアの分野と同程度とは限らないが、それでもなお、人文科学や社会科学の分野の人々は、概念モデリングが有用であることを認識している。
モデリングはソフトウェア技術者に限らず有用である。社会科学や人文科学の人々は多くの概念モデリングを行っている。
本稿は、いかに、およびなぜ我々は ConML、つまり、情報技術分野 やソフトウエア工学の非専門家のための概念モデリング言語を新たに開発するに至ったかを述べる。さらに、ConMLの設計上の主要な原理と原則や文化遺産の領域におけるこれまでの経験についても記述する。ConMLに関するより詳しい情報は、 www.conml.org や参考文献[1]を参照してほしい。
ConMLの背景と動機
人文科学および社会科学は、自然科学と比べるとそれほどテクノロジーに縁があるとはふつう考えられていない。歴史学や考古学、人類学などの分野は、少なくとも表面上は、より「柔らかく」、人に近く、かつ、モノや抽象化、機械類に遠いと考えられがちである。一般に、以下の理由でこれらは事態をより複雑にしている。
- 人文科学および社会科学の人々は、全順序関係が付けられないような、つまり、同時に取り扱うことが適切でないような複雑かつ曖昧な事柄を同時に考慮に入れようとする。
- 実在論的曖昧さ(つまり、精密でないこと)および認識論的曖昧さ(つまり、不正確性や不確実性)の両方が、考慮すべき基本的な観点である。
- 観察者(つまり、モデル作成者)の主観性は無視できず、その主観性自体が情報の重要な観点であり考慮が必要なものである。
- 人文科学および社会科学は、自然科学ではふつうに使われる、通常の仮説的演繹手法を避けることが多く、また、エンジニアリング分野で基本的な問題/解決策アプローチを必ずしも採用しているとは限らない。
このような状況の中で、文化財科学研究所(www.incipit.csic.es)の同僚たちや、他の似たような文化遺産に関する組織に属するものたちには、調査や情報の概念化およびコミュニケーションのために、概念モデルを作成したり利用したりしている。ここ数年で、正式にではないが次の二つのことが観察できた。一つ目は、モデリングの仕事を進める上で十分「よい」方法をみつけられていないことである。ここで、「よい」方法とは、上にあげたようなこの分野の特性を取り扱うことができることをいう。モデリングを用いたアプローチには、主流の、または「受け入れられた」ものはないため(ソフトウェアの世界であれば、例えばUMLがそうかもしれないが)、すべてのモデル作成者やプロジェクト、組織は、それぞれの個別のアプローチを持っている。二つ目は、UMLのような、エンジニアリングの世界から単純に「輸入」してきた手法は、破滅的に失敗することである。失敗する理由は以下の通りである。
- それらの手法は、問題/解決策パラダイムに基づくエンジニアリング分野を想定して設計してあり、文書化された問題に対する精密な解決策を与えることに特化している。人文科学および社会科学の人々は一方で、曖昧さや主観性を必要に応じて取り入れた上で、調査したり状況を文書化および分析することを望んでいる。
- それらの手法はソフトウェアシステムを構築するために提供されている。一方で、人文科学および社会科学の人々は、たいていの場合は、文書化やコミュニケーションの目的のために概念モデルを構築することに興味を持っている。彼らにとって、ソフトウェアはモデリングの主要な理由ではない。
- それらの手法は複雑すぎることが多い。歴史学者や考古学者が最新のUML仕様をきちんと把握するのを期待するのは現実的ではない。UMLの大部分の複雑さを隠蔽するようなUMLプロファイルは「抜け漏れのある抽象化」になりかねない。
- それらの手法は段階的に学習することが難しい。例えば、UMLでいえば、「instance-of」関係といった基本的なものを使えるようになるためには、ステレオタイプが何であるかというとても複雑な考え方を理解する必要がある。
- それらの手法は、人文科学および社会科学の人々が必要とするいくつかの特徴、例えば、主観性をモデリングするための明示的な機能や、「null」と「unknown」を区別する明確な意味論[4]に欠けている。
これらの理由により、我々はConMLの開発を決めた。人文科学および社会科学への応用を想定に取り組みを始めたが、あらゆる領域のあらゆるモデルに応用可能である。ConMLは極めてシンプルであり、導入しやすく、情報分野の技術に馴染みのない人々にとっても、容易にかつ段階的に学ぶことが可能である。形式的記述によるメタモデルやグラフィカルな表記、例を含む仕様すべてでも51ページに過ぎない。
情報分野の技術に関する非専門家のための概念モデリング言語、ConML。そのすべての仕様は51ページに過ぎません(あのUMLの仕様は700ページを超えています!)。
ConML言語
ConML1.5.0のメタモデルは31のクラスからなる。下の図(UMLで記述されている)は、そのうちのいくつかを示す。

主要な要素は、クラス、 属性、関連であり、通常のオブジェクト指向モデリング言語の場合と同様の意味をもつ。ConMLは多重汎化を実装しているが、多重特化はしていない。これは、プログラミング言語におけるいわゆる「多重継承」に相当するが、判別表現の明示的な存在は、明確さを向上させ、曖昧な状況を回避する。継承の繰り返しは、明確に定義された継承に関する規則によって統制される。
これらの型に関するクラスに加えて、ConMLのメタモデルは、オブジェクトや値、参照、さらには他のインスタンスに関する事柄を記述するクラスを含む。これは、下に述べるオブジェクトのバージョン化に関連して特に重要である。
ConMLにおけるその他の重要な特色として、特徴付けの差異化が含まれていることがあり、性質と名付けられている。属性と半関連(これらはその字義通りの意味を持つ)に加えて、ここでいう性質は、クラスの特徴をモデル化する役割とともに、モデルが洗練されるまで、具体的な詳細記述を未定としておくことも意図している。ここで、性質が、属性または半関連に詳細化されることによりモデルの具体化がすすめられる。
以上に加えて、ConMLのすべての特徴付けは、本質的に多値である。さらに null とunknown の意味論を直接取り扱うことができる。unknown は、情報は存在するがそれに関する知識が欠落していることを意味する一方、null は、情報そのものが存在しないことを意味する。例えば、 p.Name = unknown は、p は名前を持つが、我々がそれを知らないことを意味する。これは、p.Name = null とは大きく異なる。こちらは、p が名前を持たないことを意味する。
また、ConMLにおける特徴付けは、時相的か主観的、またはその両方のラベルをもちうる。時相的な特徴付けは、オブジェクトの変化にあたり、所有オブジェクトの新しいフェーズの記述を実現する。同様に、主観的な特徴付けは、オブジェクトの新しいパースペクティブの記述を可能とする。フェーズとパースペクティブは、オブジェクトに対して、異なる独立した側面に対応するバージョンを与えるものである。以下に例を示す。
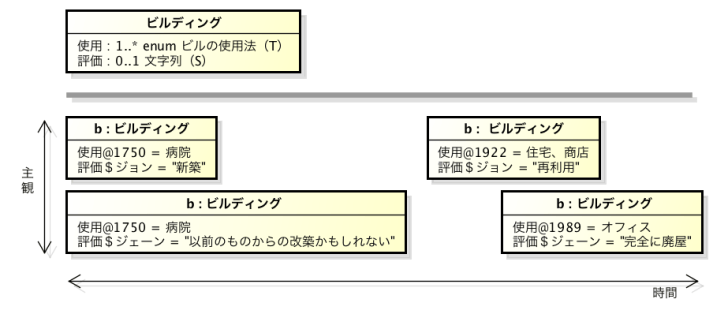
ここで、ビルディング.使用 という属性は、時相的とラベル付けされている一方、ビルディング.評価 という属性 は、主観的とラベル付けされている。太い灰色の線より下には、四つの b: ビルディング のバージョンが示されている。各バージョンは対象の記述に対して限定的である。つまり、あるオブジェクトを与えられた側面(時間および主観)に沿って「スライス」した表現であり、オブジェクトの特定のバージョンを返す。時間に関する限定子(フェーズ限定子とも呼ぶ)は、「@」記号とそれに続く時刻に関する表現(この例では、年)からなる。同様に、主観に関する限定子(パースペクティブ限定子ともよぶ)は、「$」記号とそれに続く主体に関する表現(この例では、人々の名前)からなる。ここでは、評価 という属性の値が、誰がその情報を記述しているのかに依存して、同じ時刻でも異なりうることを読み取ることができる。これは、灰色の線より上に記したクラスのモデルにおいて、「(S)」とラベル付けされていることにより表現されている。同じように、使用 という属性の値は、誰がそれを表現しているかにかかわらず、時刻によって変化していることが見て取ることができる。
ConML メタモデルは、型およびインスタンスの両レベルにおいて多言語に対応する
これはまず、型(または、OMG用語でいうM1)モデルは、複数の言語で同時に、記録および管理されることができることを意味する。クラス名や属性名などのモデル要素は、例えば、多言語で表現することができ、任意のタイミングで、必要な言語の表現によって可視化することができる。同様に、インスタンス(またはM0)モデルも、多言語によって表現することができる。特に、文字列型を持つ属性については、クラスモデルにおいて多言語とラベル付けできる。そのクラスがインスタンス化された際には、そのオブジェクトに含まれる多言語としてラベル付けされた属性は、言語毎の異なる値を持つことができる。これは、インスタンスのモデルは、多言語のアーティファクトとして容易に記録および管理可能であり、さらに、任意のタイミングで、また、必要な言語で、表示や問い合わせが可能であることを意味する。
ConML は、モデル拡張に対応する
型のモデルは、新しい要素(例えば、クラスや属性など)を追加したり入れ替えたり削除したりすることにより、拡張可能であることを意味する。拡張においては、ほぼ自由に、要素の追加、入れ替え、削除ができるうえに、拡張されたモデルは、そのベースモデルに対してリスコフ互換であることが保証される。これは、任意のタイミングで、ベースモデルに準拠する拡張された型モデルに適合するインスタンスモデルへ型変換する、再解釈規則の適用によって実現される。このアプローチにより、情報の損失を最小限に抑えつつ、型安全に相互運用可能な混成モデルを作成することができる。
これまでのConMLの実績
ConMLは、これまでにも様々な目的のために応用されてきた。主なものに、文化遺産分野の巨大な抽象リファレンスモデルであるCHARM[3](詳しくは www.charminfo.org を参照)の開発がある。このモデルは、個人レベルの研究から、いくつかの大きな国際研究プロジェクトまで、多くの研究プロジェクトに対して適用され、拡張されてきた。
さらに、ConMLは、考古学者や建築家、それらに関連する職業を目指す修士学生に対する講義「文化遺産のための概念モデリング」におけて中心的な役割を果たしている。この講義はこれまでに8回の実施しており、得られたフィードバックは大変前向きなものであった。特に、(1) 明示的に時相的および主観的な事柄を表現できること、(2) 言語が極めて単純なこと、さらには、(3) 人文科学や社会科学に対して準形式的なモデリング言語を提供するといった厳密性の付加、という点に関して評価されている。
最後に、次節で示すツール群の初期バージョンは、あるモバイルアプリを支援するためのウェブサービス群を開発する大きなプロジェクトの一部に利用されている。このプロジェクトでは、データベースではなく、文字データとマルチメディアデータをConMLのインスタンスモデルとして保存しておき、データに関するクエリは必要に応じてConMLのメタモデルに沿ってプログラムにより実行される。
ConMLの今後
ConMLの前のバージョンには、モデルビューという考え方が含まれていたが、あまり使われなかったため現在のバージョンでは省かれている。モデルビューの新しいアプローチは現在開発中であり、近い将来の仕様には含まれる予定である。モデルビューは、モデルの利用者がモデルに対してカスタマイズされた特定の階層に着目する手段を提供する。これは、例えばデータベースの実装やユーザーインターフェースの設計といった特定の目的のために、モデルを手直しする目的に役立てることができる。
加えて、ConMLに基づく包括的なツール群を開発中であり、近々公開される。このツール群は、型およびインスタンスのモデルの作成や管理はもちろん、モデル拡張や多言語、主観性や時相性の限定子、その他のConMLの機能をサポートする。さらに、モデルに対する操作の自動化のためのスクリプト言語も含む。
ConMLに興味を持ったら、最近刊行された書籍『考古学及び人類学のための情報モデリング』[2]を参照してほしい。言語の詳細な記述が豊富な事例とともに紹介されている。スペイン語版も近く発行される。
参考文献
- [1] Gonzalez-Perez, C., 2012. A Conceptual Modelling Language for the Humanities and Social Sciences, in Sixth International Conference on Research Challenges in Information Science (RCIS), 2012, C. Rolland, J. Castro, and O. Pastor (eds.). IEEE Computer Society. 396-401.
- [2] Gonzalez-Perez, C., 2018. Information Modelling for Archaeology and Anthropology. Springer.
- [3] Gonzalez-Perez, C. and C. Parcero Oubiña, 2011. A Conceptual Model for Cultural Heritage Definition and Motivation, in Revive the Past: Proceeding of the 39th Conference on Computer Applications and Quantitative Methods in Archaeology, M. Zhou, et al. (eds.). Amsterdam University Press. 234-244.
- [4] Henderson-Sellers, B., C. Gonzalez-Perez, O. Eriksson, P.J. Ågerfalk, and G. Walkerden, 2015. Software Modelling Languages: A Wish List, in IEEE/ACM 7th International Workshop on Modeling in Software Engineering (MiSE) 2015, J. Gray, et al. (eds.). IEEE Computer Society.
- [5] Hug, C. and C. Gonzalez-Perez, 2012. Qualitative Evaluation of Cultural Heritage Information Modelling Techniques. ACM Journal on Computing and Cultural Heritage. 5(2).
